

凤凰网科技讯 7月4日,阿里通义推行室秘书开源首个音频生成模子ThinkSound。该模子初度将想维链(CoT)时期行使于音频生成领域,旨在处分现存视频转音频(V2A)时期对画面动态细节和事件逻辑判辨不及的问题。
把柄通义语音团队先容,传统V2A时期常难以精准捕捉视觉与声息的时空干系,导致生成音频与画面要道事件错位。ThinkSound通过引入结构化推理机制,效法东说念主类音效师的分析进程:领先判辨视频举座画面与场景语义,再聚焦具体声源对象,终末响行使户裁剪辅导,慢慢生成高保真且同步的音频。
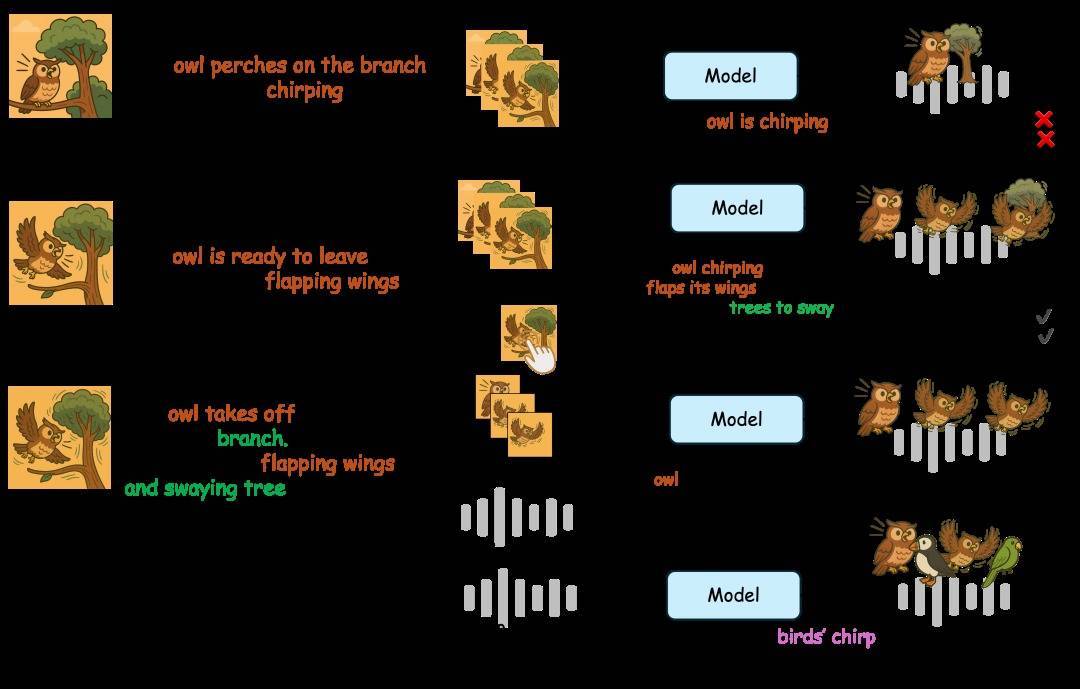
图源:通义大模子微信公众号
为锤真金不怕火模子,团队构建了首个扶助链式推理的多模态音频数据集AudioCoT,包含超2531小时高质料样本,诡秘丰富场景,并缱绻了面向交互裁剪的对象级和辅导级数据。ThinkSound由一个多模态空话语模子(弘扬“想考”推理链)和一个斡旋音频生成模子(弘扬“输出”声息)构成。
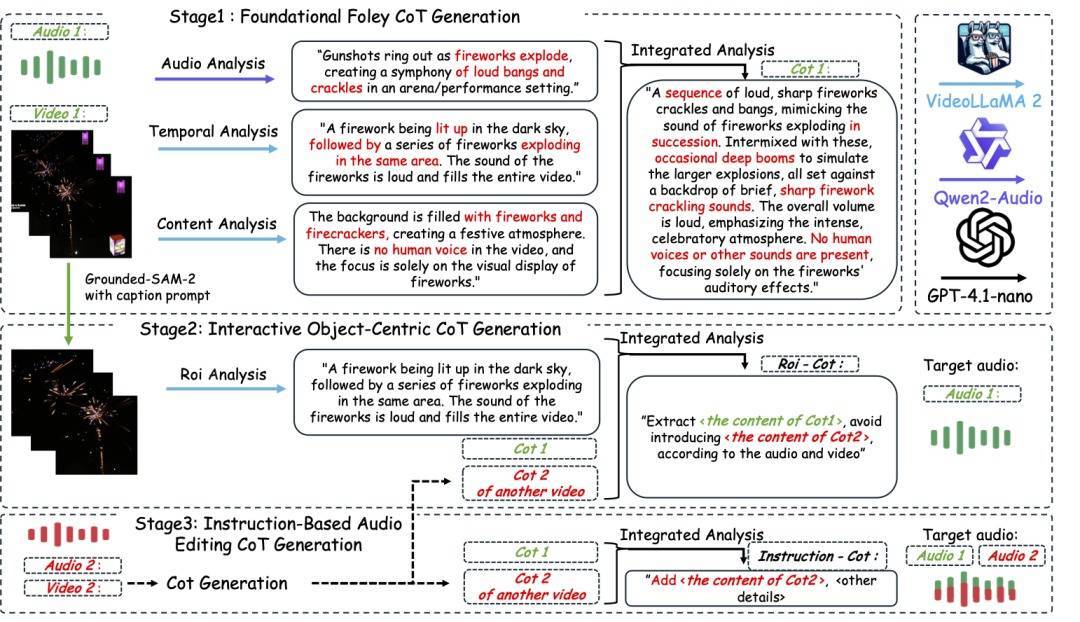
ThinkSound 音频生成模子的责任流
据悉,ThinkSound在多项泰斗测试中阐明优于现存主流时局。该模子现已开源,诞生者可在GitHub、Hugging Face、魔搭社区取得代码和模子。将来将拓展其在游戏、VR/AR等千里浸式场景的行使。
以下附上开源地址:
https://github.com/FunAudioLLM/ThinkSound
https://huggingface.co/spaces/FunAudioLLM/ThinkSound
https://www.modelscope.cn/studios/iic/ThinkSound开云(中国)Kaiyun·官方网站 - 登录入口
Kaiyun·官方网站 登录入口")
Kaiyun·官方网站 登录入口")
Kaiyun·官方网站 登录入口")